Use Paddle Quantum on GPU¶
Copyright (c) 2021 Institute for Quantum Computing, Baidu Inc. All Rights Reserved.
Introduction¶
Note that this tutorial is time-sensitive. And different computers will have individual differences. This tutorial does not guarantee that all computers can install it successfully.
In deep learning, people usually use GPU for neural network model training because GPU has significant advantages in floating-point operations compared with CPU. Therefore, using GPU to train neural network models has gradually become a common choice. In Paddle Quantum, our quantum states and quantum gates are also represented by complex numbers based on floating-point numbers. If our model can be deployed on GPU for training, it will also significantly increase the training speed.
GPU selection¶
Here, we choose Nvidia's hardware devices, and its CUDA (Compute Unified Device Architecture) supports deep learning framework better. PaddlePaddle can also be easily installed on CUDA.
Configure CUDA environment¶
Install CUDA¶
Here, we introduce how to configure the CUDA environment in Windows 10 on the x64 platform. First, check on CUDA GPUs | NVIDIA Developer to see if your GPU support the CUDA environment. Then, download the latest version of your graphics card driver from NVIDIA Driver Download and install it on your computer.
In PaddlePaddle Installation Steps, we found that Paddle Paddle only supports CUDA CUDA 9.0/10.0/10.1/10.2/11.0 single card mode under Windows, so we install CUDA10.2 here. Find the download link of CUDA 10.2 in CUDA Toolkit Archive | NVIDIA Developer: CUDA Toolkit 10.2 Archive | NVIDIA Developer. After downloading CUDA, run the installation.
During the installation process, select Custom Installation in the CUDA options, check all the boxes except for Visual Studio Integration (unless you are familiar with it). Then check CUDA option only. Then select the default location for the installation location (please pay attention to the installation location of your CUDA, you need to set environment variables later), and wait for the installation to complete.
After the installation is complete, open the Windows command line and enter nvcc -V. If you see the version information, the CUDA installation is successful.
Install cuDNN¶
Download cuDNN in NVIDIA cuDNN | NVIDIA Developer, according to PaddlePaddle Installation Steps requirements, we need to use cuDNN 7.6.5+, so we can download the version 7.6.5 of cuDNN that supports CUDA 10.2. After downloading cuDNN, unzip it. Assuming the installation path of our CUDA is C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2. After decompressing cuDNN, we take the files in bin, include and lib and replace the corresponding original files in the CUDA installation path (if the file already exists, replace it, if it does not exist, paste it directly into the corresponding directory). At this point, cuDNN has been installed.
Configure environment variables¶
Next, you need to configure environment variables. Right-click "This PC" on the desktop of the computer (or "This PC" in the left column of "File Explorer"), select "Properties", and then select "Advanced System Settings" on the left, under the "Advanced" column Select "Environmental Variables".
Now you enter the setting page of environment variables, select Path in the System variables, and click Edit. In the page that appears, check if there are two addresses C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\bin and C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\libnvvp (the prefix C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2 should be your CUDA installation location), if not, please add them manually.
Verify that the installation is successful¶
Open the command line and enter cd C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\extras\demo_suite to enter the CUDA installation path (this should also be your CUDA installation location). Then execute .\bandwidthTest.exe and .\deviceQuery.exe respectively. If both Result = PASS appear, the installation is successful.
Install PaddlePaddle on CUDA environment¶
According to the instructions in PaddlePaddle Installation Steps, we first need to make sure our python environment is correct and use python --version to check the python version. Ensure that the python version is 3.5.1+/3.6+/3.7/3.8, and use python -m ensurepip and python -m pip --version to check the pip version, confirm it is 20.2.2+. Then, use python -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple to install the GPU version of PaddlePaddle.
Install Paddle Quantum¶
Download the Paddle Quantum installation package, modify setup.py and requirements.txt, change paddlepaddle to paddlepaddle-gpu, and then execute pip install -e . according to the installation guide of Paddle Quantum from source code.
If you have installed paddlepaddle-gpu and paddle_quantum in a new python environment, please also install jupyter in the new python environment, and reopen this tutorial under the new jupyter notebook and run it.
Check if the installation is successful¶
Open the new environment where we installed the GPU version of PaddlePaddle and execute the following command. If the output is True, it means that the current PaddlePaddle framework can run on the GPU.
import paddle
print(paddle.is_compiled_with_cuda())
True
Use tutorials and examples¶
In Paddle Quantum, we use the dynamic graph mode to define and train our parameterized quantum circuits. Here, we still use the dynamic graph mode and only need to define the GPU core where we run the dynamic graph mode.
# 0 means to use GPU number 0
paddle.set_device('gpu:0')
# build and train your quantum circuit model
If we want to run on CPU, pretty much the same, define the running device as CPU:
paddle.set_device('cpu')
# build and train your quantum circuit model
We can enter nvidia-smi in the command line to view the usage of the GPU, including which programs are running on which GPUs, and its memory usage.
Here, we take Variational Quantum Eigensolver (VQE) as an example to illustrate how we should use GPU. For simplicity, VQA use a parameterized quantum circuit to search the vast Hilbert space, and uses the gradient descent method to find the optimal parameters, to get close to the ground state of a Hamiltonian (the smallest eigenvalue of the Hermitian matrix). The Hamiltonian in our example is given by the following H2_generator() function, and the quantum neural network has the following structure:
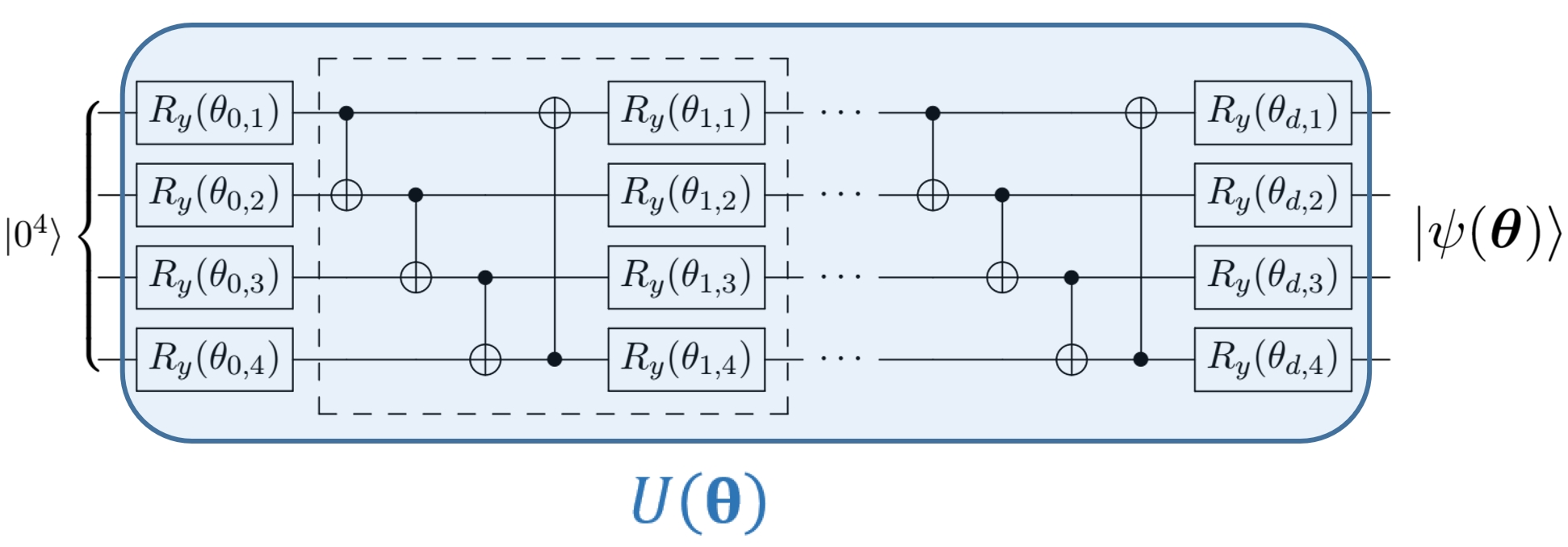
First, import the related packages and define some variables and functions:
import numpy
import paddle_quantum
from paddle_quantum.ansatz import Circuit
from paddle_quantum.loss import ExpecVal
def H2_generator():
H = [
[-0.04207897647782277, 'i0'],
[0.17771287465139946, 'z0'],
[0.1777128746513994, 'z1'],
[-0.2427428051314046, 'z2'],
[-0.24274280513140462, 'z3'],
[0.17059738328801055, 'z0,z1'],
[0.04475014401535163, 'y0,x1,x2,y3'],
[-0.04475014401535163, 'y0,y1,x2,x3'],
[-0.04475014401535163, 'x0,x1,y2,y3'],
[0.04475014401535163, 'x0,y1,y2,x3'],
[0.12293305056183797, 'z0,z2'],
[0.1676831945771896, 'z0,z3'],
[0.1676831945771896, 'z1,z2'],
[0.12293305056183797, 'z1,z3'],
[0.1762764080431959, 'z2,z3']
]
N = 4
return H, N
Hamiltonian, N = H2_generator()
ITR = 80 # Set the total number of training iterations
LR = 0.2 # Set the learning rate
D = 2 # Set the depth of the repeated calculation module in the neural network
If you want to use GPU to train, run the following program:
# 0 means to use GPU number 0
paddle.set_device('gpu:0')
# Determine the parameter dimension of the network
net = Circuit(N)
net.real_entangled_layer(depth=D)
net.ry(qubits_idx='full')
loss_func = ExpecVal(paddle_quantum.Hamiltonian(Hamiltonian))
# Generally speaking, we use Adam optimizer to get relatively good convergence
# Of course, you can change to SGD or RMSProp
opt = paddle.optimizer.Adam(learning_rate=LR, parameters=net.parameters())
# Record optimization results
summary_iter, summary_loss = [], []
# Optimization cycle
for itr in range(1, ITR + 1):
# Forward propagation to calculate loss function
state = net()
loss = loss_func(state)
# Under the dynamic graph mechanism, back propagation minimizes the loss function
loss.backward()
opt.minimize(loss)
opt.clear_grad()
# Update optimization results
summary_loss.append(loss.numpy())
summary_iter.append(itr)
# Print results
if itr% 20 == 0:
print("iter:", itr, "loss:", "%.4f"% loss.numpy())
print("iter:", itr, "Ground state energy:",
"%.4f Ha"% loss.numpy())
iter: 20 loss: -1.0717 iter: 20 Ground state energy: -1.0717 Ha iter: 40 loss: -1.1268 iter: 40 Ground state energy: -1.1268 Ha iter: 60 loss: -1.1348 iter: 60 Ground state energy: -1.1348 Ha iter: 80 loss: -1.1361 iter: 80 Ground state energy: -1.1361 Ha
If you want to use CPU to train, run the following program:
# Use CPU
paddle.set_device("cpu")
# Determine the parameter dimension of the network
net = Circuit(N)
net.real_entangled_layer(depth=D)
net.ry(qubits_idx='full')
loss_func = ExpecVal(paddle_quantum.Hamiltonian(Hamiltonian))
# Generally speaking, we use Adam optimizer to get relatively good convergence
# Of course you can change to SGD or RMSProp
opt = paddle.optimizer.Adam(learning_rate=LR, parameters=net.parameters())
# Record optimization results
summary_iter, summary_loss = [], []
# Optimization cycle
for itr in range(1, ITR + 1):
# Forward propagation to calculate loss function
state = net()
loss = loss_func(state)
# Under the dynamic graph mechanism, back propagation minimizes the loss function
loss.backward()
opt.minimize(loss)
opt.clear_grad()
# Update optimization results
summary_loss.append(loss.numpy())
summary_iter.append(itr)
# Print results
if itr% 20 == 0:
print("iter:", itr, "loss:", "%.4f"% loss.numpy())
print("iter:", itr, "Ground state energy:",
"%.4f Ha"% loss.numpy())
iter: 20 loss: -1.0621 iter: 20 Ground state energy: -1.0621 Ha iter: 40 loss: -1.1200 iter: 40 Ground state energy: -1.1200 Ha iter: 60 loss: -1.1347 iter: 60 Ground state energy: -1.1347 Ha iter: 80 loss: -1.1361 iter: 80 Ground state energy: -1.1361 Ha
Summary¶
According to our test, the current version of paddle_quantum can run under GPU, but it needs better GPU resources to show sufficient acceleration. In future versions, we will continue to optimize the performance of Paddle Quantum under GPU.
Reference¶
[1] Installation Guide Windows :: CUDA Toolkit Documentation
[2] Installation Guide :: NVIDIA Deep Learning cuDNN Documentation